The Measurement of Opinion
Louis L. Thurstone
University of Chicago
THE present investigation is an attempt to apply psycho-physical principles to the measurement of opinion. The provocation for the experiment here reported was the publication by Allport of his novel paper on "Measurement and motivation of atypical opinion in a certain group." [2]
Since it is our present purpose to suggest some possibilities and limitations to the problem of opinion measurement and to offer a solution for at least one of its many troublesome features, a brief sketch of Allport's procedure is in place in so far as it directly concerns the present experiment. Allport asked his students to write out their opinions on a number of political issues. We shall limit ourselves to the prohibition question because his scale for that question is more complete than the others. Allport selected thirteen of the opinions to constitute a series or scale. These opinions ranged from extreme "dry" to extreme "wet" with intermediate opinions arranged between the two extremes. He ranked them, in collaboration with several colleagues, in a rank order series in accordance with estimated degree of wetness. In the final series of opinions, each statement is given a serial number.
The following is a list of the thirteen statements and it will be seen that they shade off from extreme "dry" through intermediate opinions to extreme "wet".
OPINIONS ABOUT PROHIBITION
The present constitutional amendment prohibiting alcoholic liquors and the law interpreting this amendment are both satisfactory: enforcement should be made more severe.
The present amendment and interpretation are satisfactory, but a more uniform enforcement is necessary.
The laws at present are not wholly successful, but they should be upheld since
they will he successful after a generation of education and enforcement.
The laws are on the whole acceptable, but minor changes will be found necessary
from time to time.
Prohibition is correct in principle and although it cannot be completely enforced, should nevertheless be retained.
( 416)
Though prohibition is good in principle, it cannot be enforced, and therefore is actually doing more harm than good.
It should be left to the separate states to decide whether they wish to permit the open saloon.
The making of wine and beer in the home for strictly private use should be permitted.
Stares, under government control, for the sale of wines and beer not to be consumed on the premises, should be permitted.
It should be left to counties, townships, or cities whether they wish to permit the open saloon.
The sale of light wines and beers should be permitted in licensed cafes and restaurants.
Stores, under government control, for the sale of moderate quantities of any alcoholic liquors should be permitted.
The open saloon system should be universally permitted.
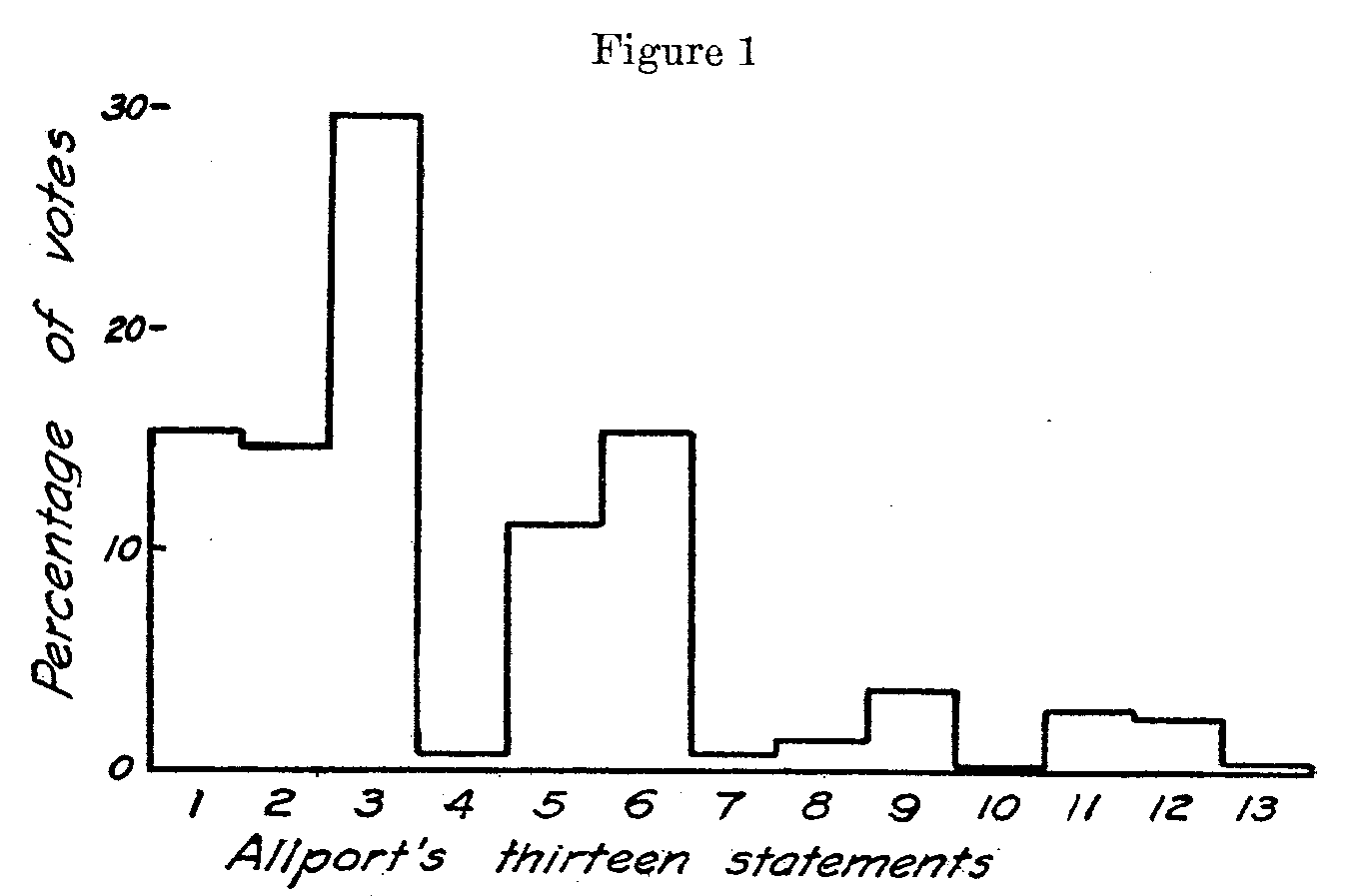
Each of Allport's students was asked to check that one statement which most nearly represented his own opinion about prohibition. A frequency count was made of the endorsements for each of the thirteen statements, and the result is indicated in Figure 1 which is a reproduction of Allport's Figure 4. This figure reminds one of a frequency distribution or a column diagram but it is quite certain that Allport did not intend that it should be so interpreted because there is really no valid measurement for the base line. The abscissae consist merely of rank orders of the thirteen statements as arranged by Allport and several of his colleagues, and for this reason one can interpret the diagram only in the sense that the height of each column indicates the frequency with which the corresponding statement was endorsed. One cannot assume that the distances on the base line have any interpretation beyond that of rank orders of the statements in the mind of the author. Nor-can one assume that the linear separations of the statements on the base line are in any sense proportional to the divergencies of the respective opinions as might, at first sight, be supposed. The linear separation of any two statements on the base line is an entirely fortuitous matter since it can be altered at will either by a difference of opinion about the rank order of the statements, or by inserting new statements in the series, or by leaving out some of them. Furthermore, it is not possible to calculate or otherwise assign a central tendency or dispersion of opinion in the group as long as the locations on the base line of the diagram are merely rank orders.
The central purpose of the present study is to solve this problem of constructing a rational method of assigning values for the base line of a scale of opinion. Professor Allport raised this problem with the writer in a recent conversation. One of the first requirements of a solution is that the scale values of the statements of opinion must be as free as possible, and preferably entirely free,
(
417) from the actual opinions of individuals or groups. If the scale value
of one of the statements should be affected by the opinion of any individual
person or group, then it would be impossible to compare the opinion
distributions of two groups on the same base.
After trying several different schemes in a preliminary way, one was found which
seemed feasible. It consists in the application of the same psychophysical
principles to the problem of measuring opinion as have been used for gray
values, handwriting
specimens, and other psychological values. The application is not made without some difficulties, however.
When we decide to represent the distribution of opinion on any given issue in the form of a frequency distribution, it is necessary first to postulate an opinion variable. This is the first restriction on the problem. By an opinion variable I mean a variable which is represented by the statements of opinion. For the prohibition question this variable might be the relative degree of restriction of individual liberty which the statements imply. Now, it is possible to hold many different opinions concerning prohibition which would not be represented at all on this opinion variable. Thus, for example, a man may hold the opinion that prohibition has increased the use of tobacco. Another man may say that prohibition has removed an important source of government
( 418) revenue. These are certainly opinions about prohibition but they do not belong on the particular variable just mentioned because they do not say or imply anything regarding the degree of restriction of individual liberty in the consumption of alcohol. Note that other opinion variables might be adopted for study or scaling which might conceivably include these opinions. It is clearly impossible to think of any sort of scale of opinion on any public issue unless we include only those opinions which naturally fall in a sequence of some sort. At the start we acknowledge, then, a natural restriction in the construction of any scale of opinion; namely, that the scale must be concerned with a specified opinion variable and that many opinions may be expressed, more or less concerned with the issue at stake, which do not belong on the scale.
Ideally the scaling method should be so designed that it will automatically throw out of the scale any statements which do not belong in its natural sequence. Such a test has been devised but its description will be deferred for separate publication.
The scaling method to be described rests on an assumption which will be stated at the outset. We shall assume that groups of individuals who hold differing opinions about the issue in question, in this case prohibition, are equally able to discriminate between any two statements of opinion. For example, two statements from the scale might be given to several groups that hold differing opinions about prohibition. They might all be asked to decide which of the two statements is the "dryer" in its attitude or implications. The two statements a and b might be such that 70 per cent of one of the groups vote that statement a is the dryer and the remaining 30 per cent that statement b is the dryer. This would give the conclusion that the first statement implies a state of affairs really a little "dryer" than the second statement but that the difference between them is not great enough so that it can be easily distinguished by everybody. The assumption under-lying the present scaling method is that the several groups would give about the same returns in their effort to discriminate between the two statements even though the actual opinions about prohibition held by the several groups might vary widely. Stated in another way, the assumption is that two individuals who differ from each other widely in their views about prohibition would find it equally easy, or equally difficult, to say which of two statements is the more in favor of prohibition. This assumption can be experimentally tested but it has not yet been done.
If this assumption is valid, then the separations between the
( 419) statements in the scale may be ascertained by psychophysical principles on the common assumption that equally often noticed differences are equal. Theoretically this assumption is not universally true. The error may be discovered in some experimental situations but it is probably small in comparison with the gross errors necessarily involved in the study of so fluid an entity as public opinion.
The scaling was conducted as follows. The thirteen statements were mimeographed on small cards, one on each card. The thirteen cards were enclosed in an envelope with a sheet of instructions. The subject was asked to arrange the thirteen cards in serial order beginning with the statement most strongly in favor of prohibition. On this statement he wrote Number 1. The last statement, which he marked 13, was the statement which he considered to be most strongly against prohibition while the other statements were given intermediate ranks. This sorting of thirteen cards was done by two hundred subjects. For accurate scaling this number should be increased to five or six hundred.
For the purposes of scaling it was necessary to determine for each possible pair of statements the proportion of the two hundred judges who considered one of the statements more strongly in favor of prohibition than the other. Since the list contained thirteen statements, there were n (n -1)/2=78 such pairs of statements. This is a rather laborious tabulation and it increases in magnitude rapidly as the number of statements in the scale increases. The results of this tabulation are given in Table 1.
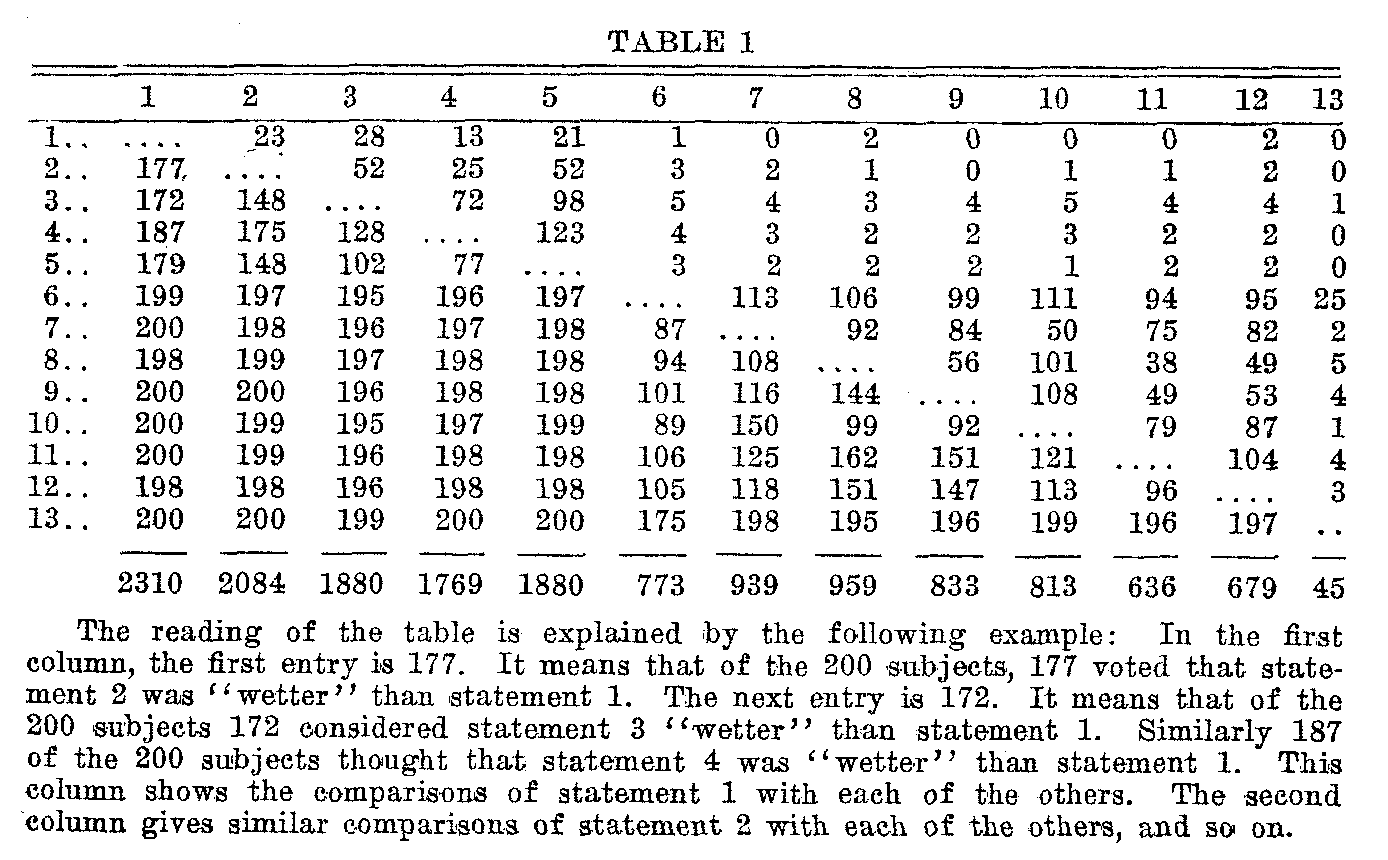
( 420)
From Table 1 it is possible to ascertain for any pair of statements the proportion of the whole group of 200 subjects that considered one more "wet" than the other. The summation at the foot of each column shows the total number of votes "wetter than" the statement in that column. Statement 1 which is represented in column 1 is one of the "dryest" in the list. Hence, there will be a large count of judgments in which other statements are considered "wetter than" statement 1. Similarly the last statement in the list, number 13, is probably the wettest. Therefore there will be relatively few votes "wetter than" it. These summations enable us to arrange the statements in rank order. This has been done in Table 2. It will be seen already in the rank
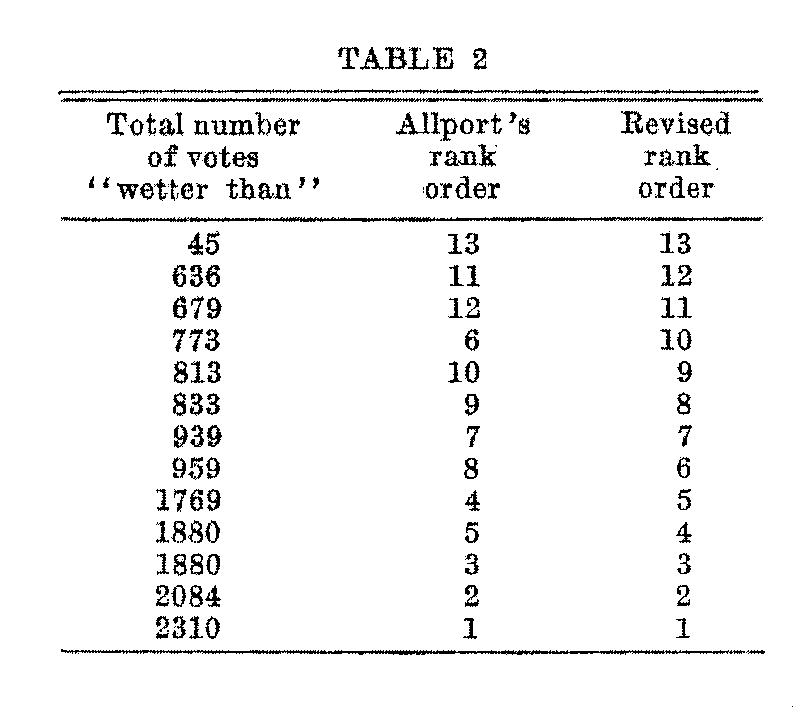
orders that the two hundred judges in this experiment did not agree with
Allport's arrangement of his statements in serial order. The most conspicuous
disagreement is for his statement 6 which according to the two hundred judges of
this study was given a rank of 10. It is clear that if we want to make a
graphical representation of the distribution of opinion in a group, it is of
very fundamental importance to have the statements arranged in a properly scaled
order. Otherwise the appearance of the graphical distribution will be deceptive.
Even the two hundred judgments of this experiment should not be considered
sufficient to establish the scale with high degree of accuracy. In Table 3
the votes recorded in Table 1 have been reproduced in the form of
proportions.
Ideally the votes should be obtained by the method of paired comparison, but that method is prohibitive because of fatigue of the subjects. For this reason I asked the subjects merely to
(
421)

arrange the statements in rank order and I deduced from the two hundred rank orders the number of times that each statement was considered "wetter" than each other statement.
The scale values of the statements cannot be determined merely by having them arranged in rank order. It is necessary to make use of the actual proportions of judgments for every pair of statements. It is at this point that we may be able to introduce a rational procedure for the construction of a scale.
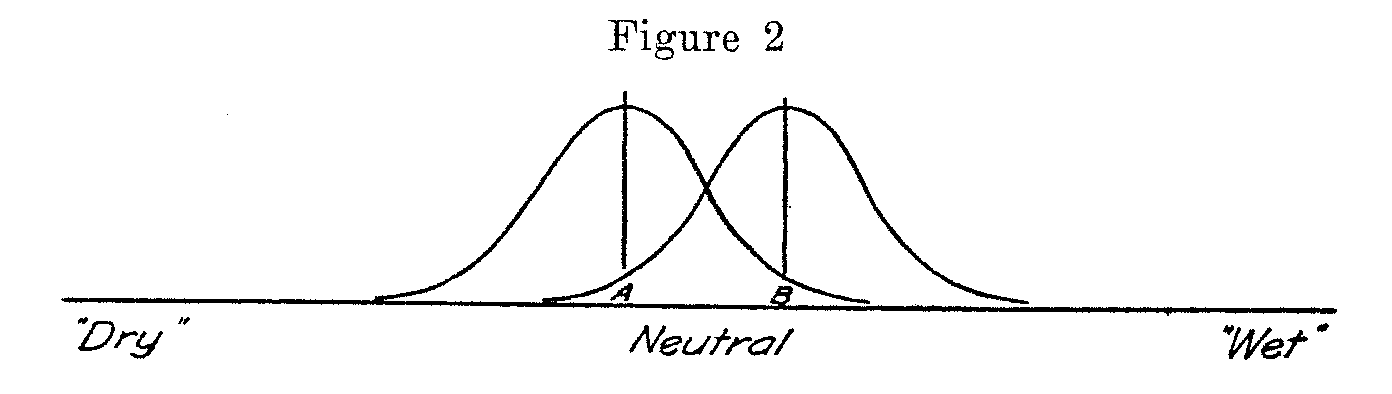
Let Figure 2 represent the desired scale and let the opinion variable be represented for the present merely by the linear extension which is labeled, "dry-neutral-wet". It is on this extension that we want to locate the thirteen statements so that we may later erect ordinates over them to show the frequency with which each part of the scale is endorsed by a group. This problem is almost identical, psychophysically, with the problem of scaling hand-writing or English composition, and the like. There is no origin, datum, or zero point. Psychological scales usually have only an arbitrary origin. We shall arbitrarily designate statement 1, the dryest, as the zero point, and all scale values will be measurements from that statement.
(422)
The next step in the construction of the scale is to define a unit of measurement, and this is really the center of the problem. We shall use as our unit of measurement the discriminal dispersion[3] of the statements, and we shall make the assumption that the statements are sufficiently homogeneous so that their respective discriminal dispersions are comparable. This assumption is implied in all psychological scales including psychological scales of educational products although I have not seen it explicitly stated. For homogeneous stimuli the following relation can be demonstrated: d=.953 σ in which d is a stimulus difference which can be discriminated correctly in 75 per cent of the attempts. It is a "just noticeable difference" (j.n.d.) which must be defined in terms of the frequency with which the difference is correctly noticed. The notation u is the discriminal dispersion or the standard error of observation for a single stimulus. It is proportional to the j.n.d. for any specified percentage of correct answers.
The standard error of observation for a single stimulus can never be observed directly. Every objective observation is a comparison of two stimuli or of one stimulus against a group of stimuli as a datum or level. Hence every observation that can be recorded must be in the nature of, comparison. For example, the level in the mercury column of a thermometer is compared with the level of the markings, and we have therefore in this simple objective observation two observational errors, one for each stimulus member of the judgment. In the present problem we assume that the two qualities or statements are sufficiently homogeneous so that the two observational errors or discriminal dispersions are at least. comparable. This will be our unit of measurement on the scale.
Let the curve A in Figure 2 represent the frequency with which statement A is perceived at different degrees of wetness or dryness. These frequencies represent the perceptions of statement A by a large group of judges. The scatter would of course be smaller if the curve should represent the same number of repeated observations by a single judge. Let the point A on the base line represent that degree of "wetness-dryness" which is most frequently read into statement A. The standard deviation of this distribution is the discriminal error, -A of A or we may call it the subjective observational error of A. Let curve B be similarly interpreted. Our assumption, previously stated, is that the statements are sufficiently homogeneous so that their discriminal dispersions may be considered equal or at least comparable.
( 423)
When the two statements A and B are compared the apparent difference between the two statements can be represented as a linear distance as long as the comparison is explicitly restricted. to the assigned opinion variable "wet-neutral-dry". It is probably a safe assumption that the subjective observational errors are uncorrelated. We shall assume, in other words, that the error for stimulus A is independent of the error for stimulus B on each occasion. This assumption is also implied in all educational product scales although I do not believe that it has ever been stated.[4]
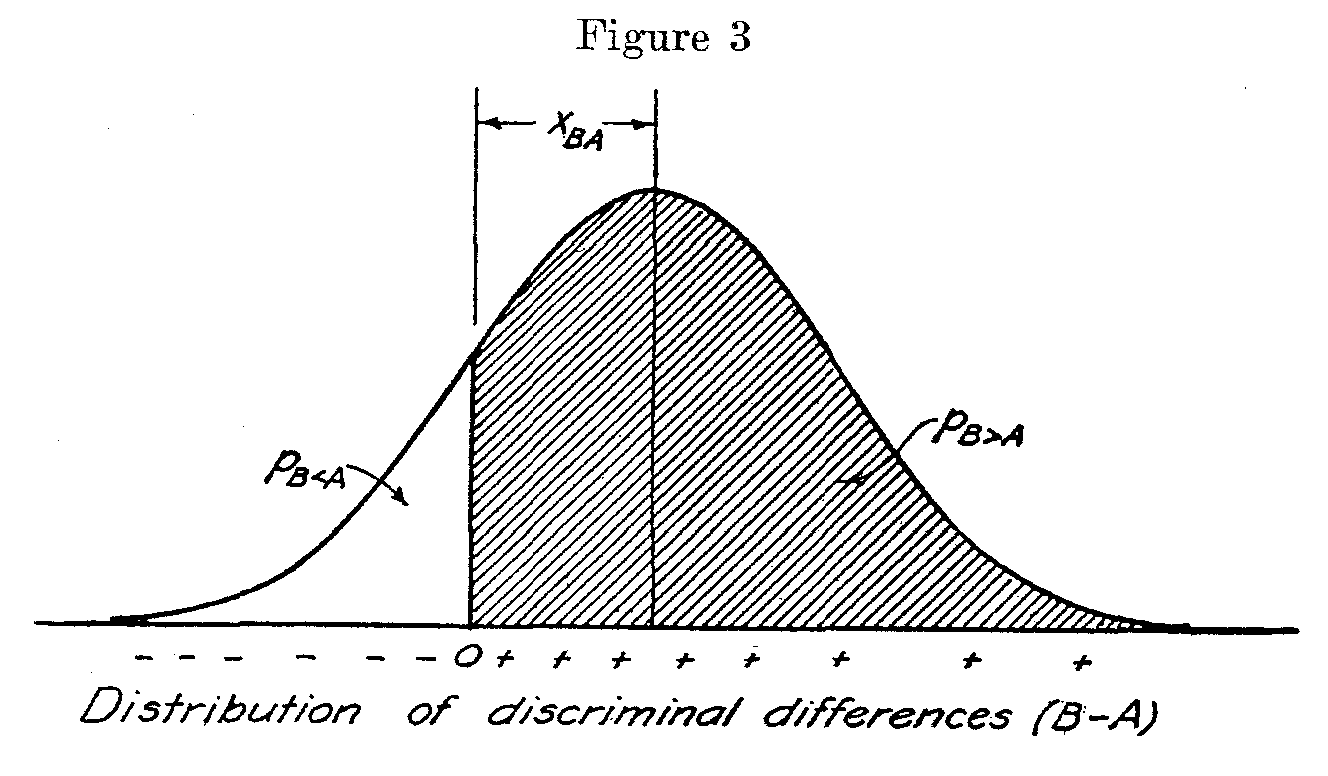
We can imagine a linear separation (B — A) for every comparison. Sometimes this difference will be positive and occasionally it will be negative. In Figure 3 these differences are represented graphically. The frequencies of observed positive differences (B—A)>O, are represented to the right of the origin. The observed negative values (B — A) <0, are shown to the left of the origin. The shaded part of the diagram represents the proportion, pB<A, in which B is judged wetter than A. The unshaded area represents the proportion, pB<A, of judgments in which A is considered to be more wet than B. The standard deviation a B—A of this surface is
σB_A = √(σ2B + σ2A ) (1)
and since σA and σB are considered to be equal,
σB_A
= σ√2
(2)
( 424)
But σ is the unit of measurement for the scale, and hence
σB � A = √2 (3)
The linear separation between the two statements A and B on the final scale should be that degree of perceived difference which is most frequent. In Figure 3 the modal linear separation is the distance xBA. This distance can be expressed in terms of the standard deviation, σB � A of the discriminal differences and the observed proportion of judgments, PB>A.
Hence
SB � SA = xBA √2 (4)
in which S A and S B are the two scale values and xBA is the sigma value of the observed proportion of judgments, P B>A.
Equation 4 enables us to ascertain the scale distance between any two statements. This, of course, does not say anything what-ever about endorsements of the statements or their frequency. In fact the scale values can be ascertained without asking anybody what he himself believes. That is a much simpler problem.
If we should use the above equation directly we might tabulate the linear separations (A—B), (A—C), (A—D), (A—E), and so on for all comparisons with statement A as a standard. This would yield a scale. We might then do likewise for the comparisons (B—A), (B—C), (B—D), (B—E), and so on for all comparisons with statement B as a standard. This would also yield a scale, and very likely the several scales so constructed would not quite agree. One such scale might be constructed with every one of the thirteen statements in turn as a standard. It is our next problem to determine how these scale values are to be weighted for the construction of a single scale based on all the available stimulus comparisons.
In order to determine the scale distance between any two statements A and B so that all of the available paired comparisons may be taken into account we might arrange the scale distances as in the following table.
(SC � SA) � (SC � SB) =(SB � SA)
(SD � SA) � (SD � SB) =(SB � SA)
(SE � SA) � (SE � SB) =(SB � SA)
(SF � SA) � (SF � SB) =(SB � SA)
in which the left hand members are determined by the observed proportions and by equation 4. We should then have the same
( 425) numerical value for the scale distance (SB—SA) from all of the equations except for the observational errors in the experimentally determined proportions.
Since the standard errors of the numerical values of (SB —SA) from the different equations vary, it is necessary to weight these values in determining a final scale distance for (SB —SA). In the first equation of the above table we have
(SC—SA)—(SC—SB )=(SB—SA) (5)
The standard error of (SB —SA) may be written
σba = √(σ2ca+ σ2ca) (6)
in which
σba =standard error of (SB—SA)
σca =standard error of (S C —SA)
σcb =standard error of (SC—SB)
By equation 4, the standard error of (Sc —SA) is the same as the standard error of xCA and similarly for other paired comparisons. But
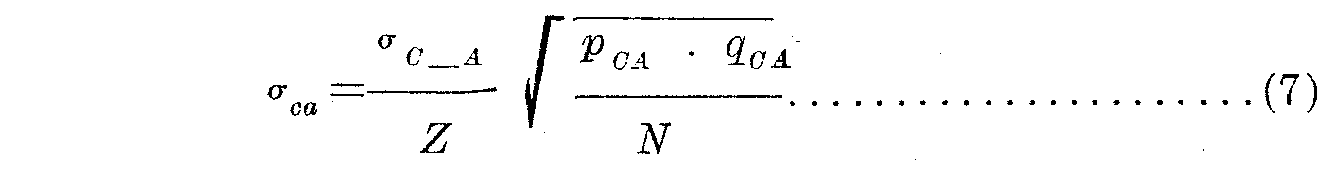
in which
σCA =standard error of xCA
σC �A=standard deviation of the distribution of discriminal differences for stimuli C and A
σC �A= σ√2in which σis the unit of measurement
Z = ordinate of the probability curve at xCA when area of surface is taken as unity and σis unity
N = number of observations
pCA =proportion of judgments "C>A"
qCA =1—pCA
Since in equation 7 the value of N=200, constant throughout the experiment, and since σC �A is assumed to be constant, they may be dropped in establishing a weight for the numerical value for each equation in the above table. Hence σca will be proportional to
(√ (pCA x qCA )) ZCA (8)
and, similarly,
( 426)
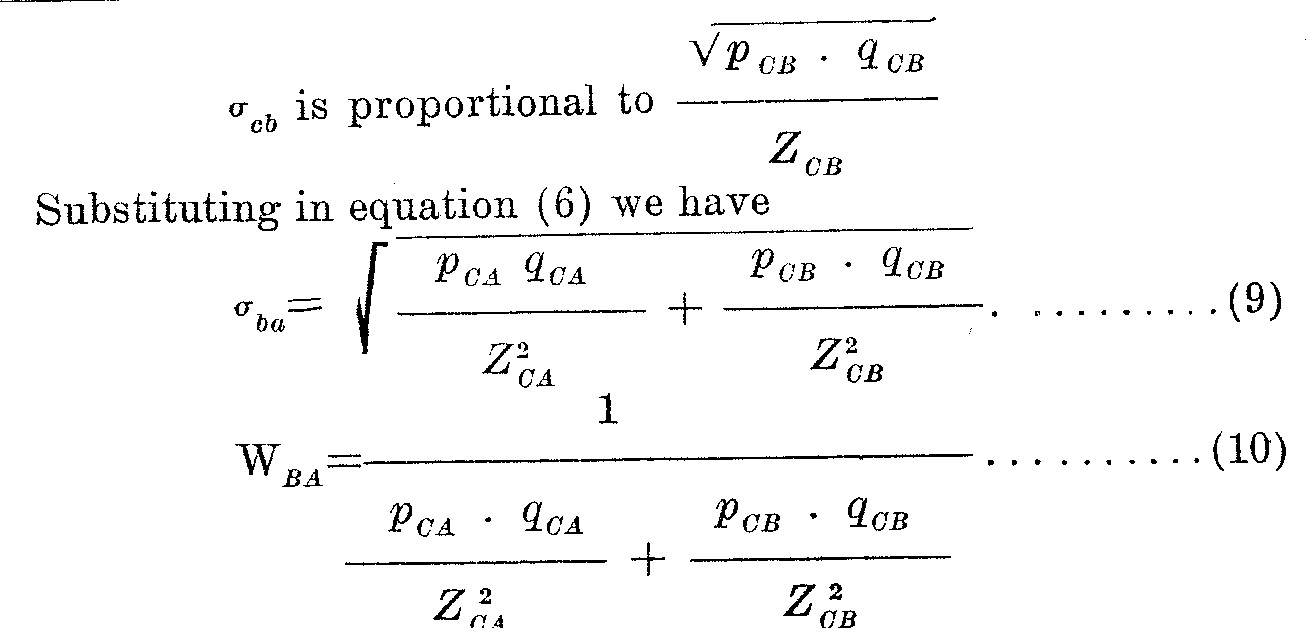
If the value of (SB —SA) in each of the equations of the above table be given its appropriate weight as shown by equation (10) the weighted average of the several numerical values of (SB —SA) will be the scale distance between the two statements A and B. It should be noted that such an average takes into account the comparison of every one of twelve stimuli with A as a standard, and also the comparison of every one of twelve stimuli with B as a standard. It is clear that in a similar manner one may ascertain the weighted average scale distance between B and C, between C and D, and so on.
The procedure could be simplified if there were no holes in a complete table of paired comparisons, but unfortunately this circumstance is unavoidable. A complete table of paired comparisons would show the proportion of judgments A<B, A<C, A<D, A<E, . . . A<K. If A, B, C, are adjacent stimuli, they will give experimental proportions greater than zero and less than unity. For the judgments A<E, A<F, . . . A<K, one will obtain either zero or
(427) unity because these pairs of stimuli are perhaps so widely divergent on the scale that they are always unanimously discriminated, and no direct scaling is then possible. One can scale such wide separations by parts so that there is a measurable amount of confusion of judgment in each part.
We now proceed to scale the thirteen statements about prohibition by means of equations 4 and 10. The first step is to ascertain the value.
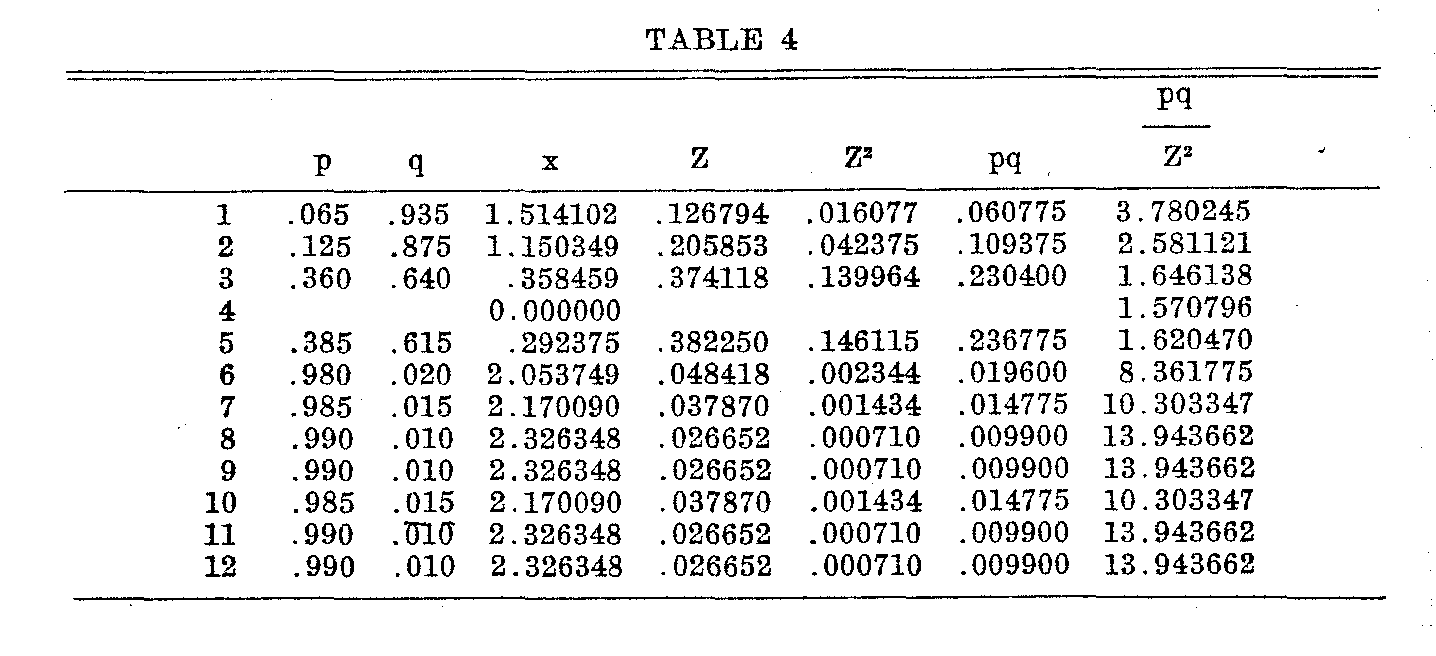
pq / Z2
for use in equation (10) for each of the entries in Table 3. This has been done for statement 4 in Table 4. The first column in this table shows merely the numerical identification of the statements. Column q is merely the complement of p. Column x shows the sigma value of the given value for p and has been read directly from the Kelley-Wood tables. The item z was read directly from the same source. The last three columns are self explanatory. One table like Table 4 was prepared for each of the thirteen statements. It is necessary to carry the calculations to five or six decimals in this instance because of the coarseness of the original scale which necessitates the use of small value of p and q.
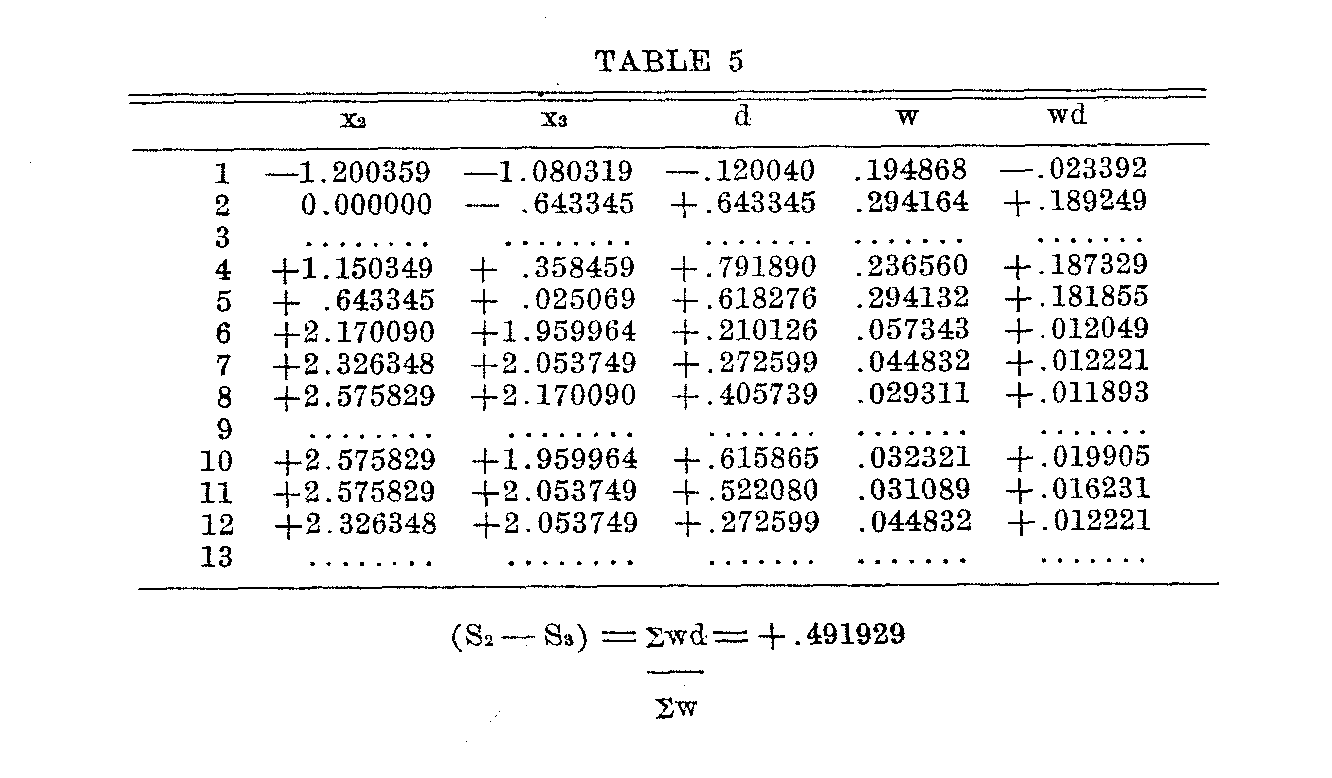
In Table 5 we have the calculation of the scale distance (S2—S3) as an example. The first column shows again merely a numerical identification of each statement. The second column
(428) and third column are copied from tables similar to Table 4. Column d is the difference (x2-x3). The, next column is the weight w23 by equation 10 and the last column is the weighted difference wd.
The scale distance (S2-S3) =+.492 which should not be interpreted as accurate beyond the second decimal.

Since there are thirteen statements in the scale there will be twelve tables like Table 5. If the thirteen statements of Table 2 are arranged in rank order by the total number of votes, we get the twelve comparisons shown in Table 6. Each of the entries in Table 6 was determined by a calculation like that of Table 5. The scale distances between adjacent pairs of statements are shown in Table 6.
From these scale distances between adjacent pairs of statements we obtain the final scale values of Table 7 which constitute our main objective.
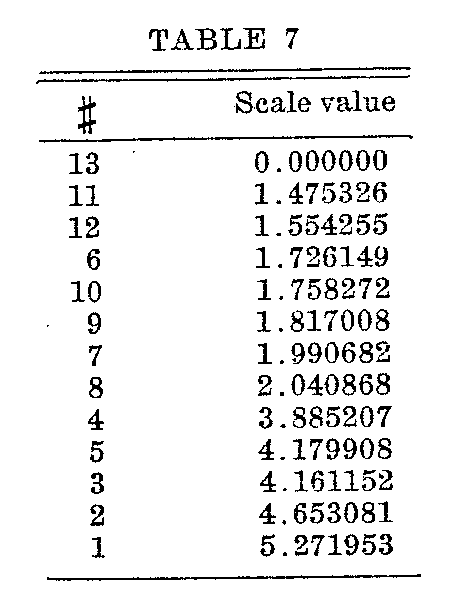
The final scale values are shown graphically in Figure 4. Inspection of this figure shows immediately that there are wide
(429) ranges in the scale which are not represented by any statements of opinion. Also it appears from the graph that seven of the thirteen statements represent more or less the same attitude since statements 6, 7, 8, 9, 10, 11, 12 are all scaled within the rather narrow range of .6 of a scale unit.
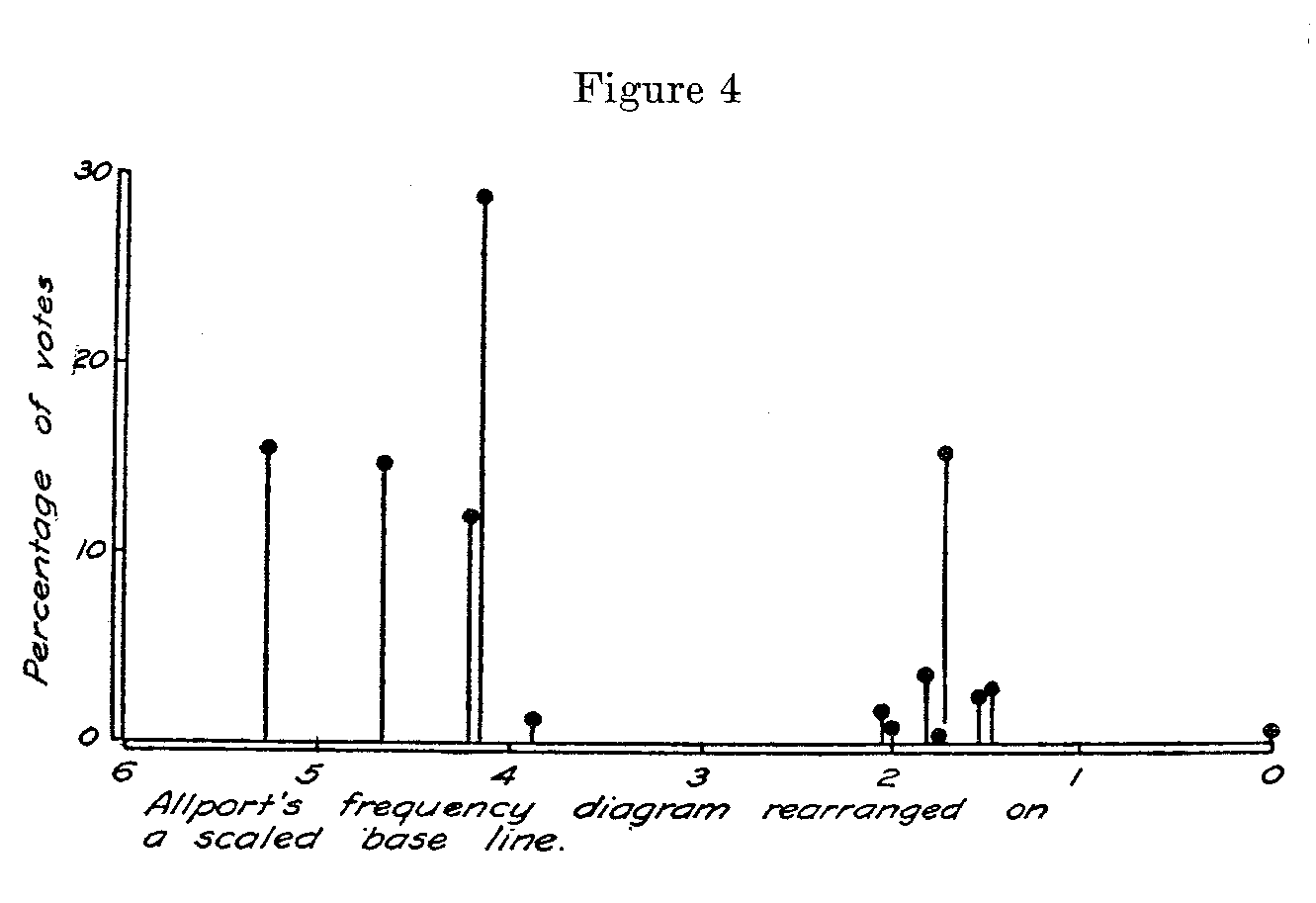
The final scale takes the appearance of Figure 4 which should be compared with Allport's figure 4 reproduced here as Figure 1. It is clearly not worth while to attempt a graphical representation of the- distribution of opinion except as a bar diagram. The gaps between statements 4 and 8 and between statements 11 and 13 are too great to allow a legitimate frequency distribution to be drawn and the separation between them is so great that their separation cannot be accurately determined beyond the fact that they are too far apart to make possible a true representation of the distribution of opinion.
In order to construct a scale for the measurement of opinion, it is advisable to start with a rather large number of statements from which a smaller number may be selected for the final scale. These should be so selected that they are approximately evenly spaced. When a frequency surface is erected on such a base line it will be possible to compare it with the corresponding distribution of opinion in another group. With a rational base line as here described it will be possible also to calculate measures of
( 429) central tendency and of dispersion for each group but that could not be satisfactorily accomplished with the thirteen statements of Allport on prohibition because of their extremely uneven spacing.
It may be possible to simplify considerably the procedure if, say, one hundred statements were sorted by several hundred subjects into ten piles to represent equal appearing intervals on a scale. The cumulative frequencies on such a scale might conceivably be treated as a phi-gamma function. The scale values of the statements might then be determined by a procedure analogous to the calculation of the limen or 50 per cent point in the usual psychophysical problem. The relative ambiguity of each statement would be measured by the standard deviation of the phi-gamma function for each statement. The final scale would consist of a selection of statements which are as far as possible evenly spaced on the scale and which have the highest possible precision. An experiment to ascertain the validity of such a simplified procedure will shortly be tried. Such a procedure assumes of course nothing about the shape of the distribution of opinion in any given group.
The main principle in the measurement of opinion to which the present paper is devoted is the construction of a rational base line for describing the distribution of opinion by which equal intervals on the scale shall represent equally often noticed shifts in opinion or equal appearing opinion differences. This principle of a rational scale enables one to compare several groups as to distribution, central tendency, and dispersion of opinion on any stated opinion variable, irrespective of the shape of that distribution or the amount and direction of bias in each of the groups.