A Study in Statistical Ethics
Albert P. Brogan
I.
IN recent years the study of ethics has gained much, both in breadth and in reliability, from the development of what has been called "comparative ethics." This may be defined as the study of the actual moral attitudes of different peoples at different times or places. It ascertains these moral attitudes by studying actions, feelings and beliefs, as recorded in arts and religions, customs and laws. Previous work in comparative ethics has been primarily historical, and has used what is called the genetic or evolutionary method. This method has given very interesting results in the writings of L. T. Hobhouse and many other writers.[1] But it has tended to lay undue emphasis on the study of the past. This study of the past has helped to explain the present, but cannot be a substitute for a description of the present. Present facts are more important to us than are past facts, and they are more easily known by us in most cases. About one half of comparative ethics should be a study of contemporary morality. It is the contention of the present writer that this part of comparative ethics should be mainly statistical. This statistical ethics should
( 120) not pretend to be a substitute for theoretical or philosophical ethics, though it may later give much help to the philosophy of ethics.
In earlier papers I have given philosophical or analytical arguments to show that all values are relational.[2] All facts about value are really facts about the relation of better or worse. The relation of better or worse is the fundamental value category or universal. So moral values, if this theory is true, must be comparative values. If moral values are comparative or relational, they might form a series or scale. Such a series or scale might be something to be discovered by investigation of moral facts unknown to popular opinion of the present day, or this series or scale might be definitely embodied in the popular opinion of to-day. The present paper will throw some light on this question. The important task of comparative ethics is to study moral attitudes about this scale. A philosopher may argue that the popular attitude about this moral scale is misleading or inadequate. But the task of comparative ethics is simply to make a dispassionate study of the actual prevailing attitudes. If we are to make a study of popular opinion to see what moral scale it contains, we must have some statistical tool or method. It happens that such a tool or method has been worked out very carefully in recent years. It is called the statistics of "correlation." This method gives a way of measuring the amount of similarity or dissimilarity among different scales or rankings.[3]
( 121)
I have not been able to find any anticipation of this line of approach to ethical study. Professor L. T. Hobhouse gives an example of correlation in his Morals in Evolution, but for a quite different purpose.[4] Professor F. C. Sharp and others have collected statistical answers to questions about morality, but I have not found any use of correlation in these writers.[5] The greatest anticipation is in the work of F. G. Fernald.[6] He used a form of correlation for the sake of comparing the moral rankings made by normal persons with the rankings made by defective or delinquent persons. His selection of topics was made by himself, and is clearly of more interest to abnormal psychology than to ethics. Other studies in Fernald's footsteps have been made by F. L. Wells, L. Jacobsohn-Lask, S. C. Kohs, and others.[7] But none of these men has used correlational statistics as an aid to the study of ethics.
As an example of the nature of statistical ethics and as evidence of the value of its results, I give below a statistical study of one phase of popular morality. By popular morality is meant especially the moral opinions of those who have never had any set training in systematic ethics. The purpose is to see if there is among such people a definite scale of moral values in some fairly uniform order of better and worse.
II.
The first step in the study of popular morality is the selection of some definite list of topics to be ranked by the public. This list should be made by the public itself. If the
( 122) investigator makes his own list, popular opinion may not have a fair chance to express what it has "on its mind."
For the present experiment, the list of topics was made by men and women students at the University of Texas. The list was made at the very start of a beginning course in ethics in the Spring of 1919. Each student was asked to make a list of the "ten worst practices" among students in the university. Lists of best practices were asked for, but they were disregarded for the present study because they were more difficult to arrange. When these names of worst practices were compiled, it was found that sixteen practices stood out as being mentioned most frequently. These practices were put in alphabetical order as follows: Cheating, Dancing, Drinking, Extravagance, Gambling, Gossip, Idleness, Lying, Sabbath Breaking, Selfishness, Sex Irregularity, Smoking, Snobbishness, Stealing, Swearing, Vulgar Talk. For the home community only eight practices stood out as having ten or more votes. Each of the eight was in the first list, so no use was made of them.
The making of this list has been repeated more than a dozen times during the past three years. The practices listed were very nearly the same, though there was considerable difference in the order of frequency of mention. In the university list, cheating, idling, and gambling were usually the ones most frequently mentioned. In the list for the home community, stealing, drinking, and sex irregularity were most frequently mentioned. The list of sixteen practices was repeated year after year with only slight variations. Vulgar talk and sabbath breaking were omitted more frequently than any other topics. In the university list, the most frequent additions were disrespect, criticism, and aimlessness. In the list for the home community, the additions were speeding, profiteering, and bootlegging. However, the first list was kept unchanged, so that exact comparisons could be made with one list during several years.
If the limits of this article did not forbid, it would be interesting to make a study of those practices which were
( 123) named by less than ten persons. Over a hundred of these practices were compiled. Many of them are as interesting to study as those which were more frequently mentioned by the students. It would have taken too much time and energy to get all of these ranked. Perhaps later a study can be made of some of them. Naturally the practices for the home community are usually more serious than the university practices.
The reader may naturally wonder why "practices" were ranked rather than specific or individual actions. The answer is that popular morality seems to give a readier response concerning practices than concerning more individualized items. Moreover it is very difficult to describe an action so as to make it purely specific or individual; it tends to be "that sort of an action." It would be almost impossible to get public opinion to make such descriptions. The aim of the present article made it necessary to use the more general notion of practice. More individualized items must be left to later studies.
III.
This list of worst practices was put in alphabetical order and given to about a thousand students at the University of Texas. For the present study use was made of the answers of 242 men and 292 women who were in the introductory ethics course during the first week of each term from the Spring of 1919 to the Spring of 1921 inclusive. Students in other courses, in Summer School, in advanced ethics courses, and late registrations were all omitted. The introductory ethics courses have no freshmen, many sophomores, and a moderate number of juniors and seniors.
The instructions read as follows: "Alter considering all aspects, which of these practices do you consider worst? Place the number 1 opposite this. Mark the next worst 2, and so for all the rest." No further explanations or instructions were given, except that students were asked to give their own opinions. The student was told not to sign his name but to indicate his or her sex. The papers for the two sexes were tabulated separately. It was hoped that having
( 124) the papers unsigned would give more honest and sincere answers. The students were not timed, but were made to complete the ranking before they left the room.
Reasons have been given above for having these practices ranked in order of "better and worse." Of course if my theory were false, and if all these practices were considered wrong but equally wrong, then no definite ranking could have been given. On the other hand, if we find a very definite ranking, that will be a partial verification of my theory about "betterness." The students might have been asked to rank the practices according to some other standard, such as blameworthiness. But I think that such a standard is less fundamental, so I have left it for later investigation.
IV.
A careful examination of Table A will enlighten the curious reader more than any of my paragraphs could do. But I add some short descriptions and explanations.
The reader will observe that the practices in column 1 are listed in the order of badness given by the women (as numbered in column 3). A study of the men's ranking in column 2 with the women's ranking shows the following results. There is a very definite statistical order. There is less bunching or approximate equality than might have been expected. From a statistical point of view the two rankings are almost incredibly similar. In this phase of popular morality there seems to be no large sex difference.
The rankings given in columns 2 and 3 show that there are only three slight differences between the men's rank and the women's rank. The men rank gambling worse than drinking, but the women rank drinking worse than gambling. The arithmetical averages in columns 4 and 5 show that the difference is primarily about drinking. The women rank sabbath breaking as worse than swearing, but the men reverse the rank. The arithmetical averages for the two practices are nearly the same in both sexes. The last difference concerns gossip, which the men rank as 13 but the women rank somewhat worse as 10. Here it will be
( 124)
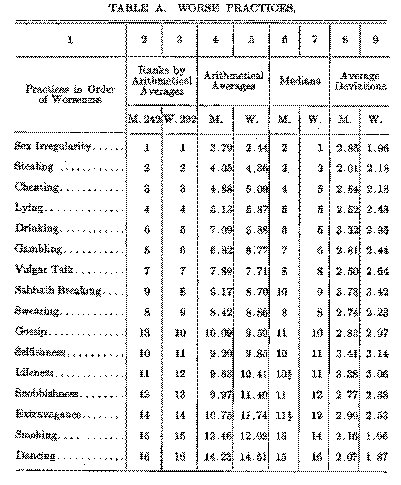
noticed that the arithmetical averages differ by only one half of a point. This displacement of gossip naturally causes a displacement of one point in the rank of each of the following practices, selfishness, idleness, and snobbishness.
Although these three slight differences are the only ones in the rankings given by the two sexes, there are some other facts to be noticed concerning the arithmetical averages in columns 4 and 5. Both men and women place sex irregularity as the worst of the sixteen practices, but the women
( 125) are more nearly unanimous than the men and so their aver-age is smaller. While both men and women rank idleness, snobbishness, and extravagance in the same order, the women give larger averages for all of them. This would seem to indicate that the women thought these practices relatively less objectionable. In the men's ranking, smoking is naturally given a larger average as being less objectionable.
The facts noticed above are very minor divergences. The general impression, just from an ordinary inspection, is that of overwhelming uniformity and agreement. Let us now turn to a definite statistical formulation of the correlation between the rankings given by the men and by the women. For the benefit of a few of my readers who may not be familiar with some recent developments in the statistics of correlation, I give in the following paragraph a brief and elementary explanation of coefficients of correlation.
There are several methods of obtaining correlation coefficients (symbolized by r), but I shall use the Spearman rank-difference method. The other methods have been used on the same data, but they have not given a figure differing by more than one per cent from this method. When we compare the different possible ranking: for our sixteen practices, we notice that the extreme cases would be that the rankings might exactly coincide or they might be exactly reversed. If they were exactly reversed, the sum of the squares of the differences between the two rankings would be 1360. If they coincided, this sum would be zero. If the two rankings were merely connected haphazardly by independent shufflings of cards, the sum of the squares of the differences would tend to be about 680. This haphazard point is called zero correlation, and other correlations are measured up or down from this point. For our present purposes we are concerned only with the positive correlations between zero and identity. When the sum of the squares of the differences equals 680, we say that r equals zero. When the sum equals zero we say that r equals 1. Intermediate sums are represented as percentages of 1. Thus when the sum is
( 126) about 340 we say that r equals .50. The mathematical formula used here may be found in any recent book on statistics.[8]
When the sum of the squares of the differences between column 2 and column 3 is calculated, it is found to be 16. This means that r, the coefficient of correlation, is equal to AS. In other words, the two rankings lack only two per cent of being identical. They are 98 per cent of the distance from a chance correlation to a coinciding correlation. As correlations go, this correlation is very high. Usually a correlation of .70 is considered high.
V.
When we calculate the measure of unreliability for the correlation between column 2 and column 3 in Table A, we find that it is very low. Since r is .98, the standard error for r is .01. This means that if such tabulations were repeated a large number of times under the same circumstances, two-thirds of the correlations would fall between .97 and .99. The probable error of our coefficient of correlation is approximately .007. So our correlation has an extremely high degree of reliability.
VI.
In columns 8 and 9 of Table A, an account is given of dispersion. I have given the average deviation rather than the standard error, because the latter seemed inappropriate for anonymous votes. Some apparently erratic votes are merely careless or mischievous. The standard error, by squaring all deviations from the arithmetical average, might be unduly influenced by a few such votes.
The average deviations for the men average 2.78. For the women the average deviation is 2.51. The average deviations are large for drinking, Sabbath breaking, selfishness, and idleness.
( 127)
VII.
In Table B, I give the more important correlations obtained at the University of Texas in securing the results which are condensed in Table A. Unfortunately there is not room here for all of the original rankings. The correlations are all monotonously high, even among the smaller sub-classes on which the totals are based. As all correlations here are positive, I have omitted the positive sign. Notice the similarity between the freshmen (at the beginning of the school year) and the juniors and seniors.

( 129)

VIII.
In Table C, I give the results of comparing students' rankings for the same sixteen practices in different states. The same blanks were given to students at the University of Chicago, the University of Kansas, and the University of Wisconsin. These were compared among themselves and with the University of Texas. For convenience in comparison and because of the small sex difference, the men and women were tabulated together instead of separately as before. The correlations are again all positive and very high. As a matter of fact the only practice about which real disagreement seems to prevail is sabbath breaking. At Texas this is ranked 8 or 9. At all the Northern universities, sabbath breaking is ranked 14. This difference is probably a general difference between the North and the South. Perhaps it might be called more religious or ecclesiastical than purely ethical. With sabbath breaking omitted, the women at Texas and at Chicago have a correlation of .99. This is virtual identity. But even with the difference about sabbath breaking, all correlations are very high.
The four universities here studied are probably good representatives of American popular morality. I hope that I can later secure figures from other universities in the far East and the far West. But I suspect that only a large element of foreign-born students could keep the correlations from being very high. I have not yet secured any data on popular morality outside of America.
IX.
Before we consider some of the ethical and philosophical interpretations of the above statistics, let us briefly outline
( 130) certain of the future developments of statistical ethics. Some of the lines of investigation listed below have been begun by the present writer, but he has no desire to monopolize either the method or any, part of the field of statistical ethics. Such a method obviously requires the collaboration of many different workers. Since it is a scientific method, it will give the same result for all careful workers with the same data.
There is much work still to be done with this same list of sixteen worst practices. Many different localities should be studied both in America and in other parts of the world. In future years, both near and remote, these statistics should be repeated, so as to see if popular morality is changing. It is interesting but useless to wish that we could have such statistics for the different civilizations which have flourished during the past few thousands of years. But we can see that future generations know both the popular morality and the philosophical ethics of the present day.
The present study has been confined to university students. Obviously similar studies should be made of all the different classes in each community. Special attention can profitably be given to the different professions.
The present study has been concerned with what may be called "general worseness." A separate study should be made of double standards, to see which actions are judged to be worse when done by men and which are judged to be worse when done by women.
It might be thought that while groups will agree as to which actions are worse than others, they might not have any uniformity of opinion as to which are more frequently practiced. But this is not the case. There is a uniformity about frequency at the University of Texas which is fully as marked as the uniformity about comparative badness.
A more difficult but very important study is the investigation of what standards public opinion is using in making such rankings as have been given in the present article. There are two ways of doing this. One way is to ask each student why he put each practice in the given rank. The
( 131) other and more scientific method is to make a correlation between the rank for comparative badness and other ranks which definitely use different moral standards. All the different standards could be used, sentimental and teleological, egoistic and altruistic and universalistic, hedonistic and non-hedonistic, and so forth.
Then other topics could be ranked, some lists made by other groups and some lists made by the investigator for special purposes. More specific or individual acts should be studied. Good actions or practices should be studied, as well as all sorts of experiences, ambitions and ideals.
I should regret any hasty attempt to use statistical ethics for the purpose of giving mental or moral tests to individuals, until we have a much larger and more accurate set of facts for a foundation. But it is obvious that in time some such use will come. Some will regret such a possibility. It would certainly be undesirable in the wrong hands, but there is no reason why such tests cannot some day be handled wisely.
There are many other future uses, such as the securing of more deliberate and critical rankings from persons who have studied or are studying ethics. The Thorndike-Hillegas "order-of-merit method" might be used for a precise measurement of values.[9] But perhaps we have listed enough possibilities to show that there is a large field for profitable work.
X.
Let us turn now to a short consideration of some of the philosophical results and interpretations both of the special study made in this article and also of the general use of statistical ethics.
We talk much about public opinion and the group mind. Some valuable studies have been made in this field. But public opinion should be studied in its factual detail more than has been done. Public opinion is the result of many
( 132) minds, whose similarities and differences must be studied statistically.
It should be stated most emphatically that it is not the purpose of this article to set up public opinion or popular morality as a standard or norm to be obeyed. We have studied the scale of moral values found in popular opinion. This has been mere description of actual facts. How far this popular opinion is to be followed by enlightened minds is a totally different and separate question. The scale which we have discovered is "mediocrity" in the strictest sense of that word. It expresses the average or middle opinion of a group. Perhaps some persons have more en-lightened and more reasonable views. But those who differ too much from the average need to be sure that they are more reasonable than their fellows rather than less reasonable.
Whether public opinion is correct or normative always or usually, the fact remains that public opinion is very influential. It is so influential that it must be known, and it can be known accurately only by such methods as we have been studying in this article.
Even if public opinion were always false, it would still demand study so that it could be efficiently corrected or improved. You cannot cure what you do not understand. This applies to all persons who deal with public opinion. Teachers of ethics, especially, are beginning to realize that they need to know what their students think when they first come to the classroom. In this connection statistical ethics is helpful and interesting both to students and teachers.
XI.
The study of ethics may be made empirical in many ways. One way is historical or genetic study; another way is the study of consequences of actions. Both of these ways are very helpful. But the statistical method can give help to empiricism which no other method can give. History relies upon the unverifiable past, consequences run off into the inaccessible future, but statistical ethics gives us an un-
( 133) -questionable confrontation with present-day fact. Interpretations of the facts may differ, but the facts are there to be studied.
Some philosophers seem to pride themselves on having a philosophical method which is distinct from the method of the sciences. The difference seems to be that two independent philosophers seldom hold the same theory and that there is no method of controlling and "checking up" their theorizing. Statistical ethics cannot be a substitute for necessary theories, explanations, and interpretations. But statistical ethics can give a factual basis from which to start and to which to return. It can give a method by which we can "control" our theories. So we may expect statistical ethics to be rejected by those who object to all use of scientific method. Statistical ethics will be objectionable to those who exalt the dogmatic or apologetic spirit in philosophy. Statistical correlations obviously demand the investigative point of view.
XII.
These statistics suggest a discussion of many topics in ethical theory, but our space is used. The remarkable uniformity discovered calls for explanation, and raises anew the old problem about the objectivity or subjectivity of value. A sceptic will naturally wonder how sincere these rankings were, even though they were anonymous. Psychologists will be curious about the relation of these conscious attitudes and standards to the actual motivation of conduct. But all these problems and many others must be left to later discussions.
There is just one point in ethical theory which I cannot resist discussing very briefly. This is the question as to the fundamental value concept or category. I have referred above to the "melioristic " theory that all values are ultimately concerned with the better and the worse. According to this theory valuables are not to be classified as right or wrong, good or bad, except incidentally. Fundamentally valuables are in a scale of better and worse. Does not
( 134) our study of popular morality indicate a structure in accord with the theory of "meliorism?" Elsewhere I have given philosophical arguments to prove this theory. But surely the inductive and statistical study of the facts of human valuation. gives some empirical verification to the theory of the better and the worse.
A. P. BROGAN.
THE UNIVERSITY OF TEXAS.